Git permite registrar y organizar las modificaciones realizadas al código en un proyecto de programación (o en realidad, cualquier cosa que involucre texto plano). Además permite revertir cambios y sincronizar el “registro” con otras copias remotas. Esto lo hace una herramienta muy utilizada para el desarrollo, sobre todo cuando involucra múltiple personas.
Instalación de Git
En Debian/Ubuntu y distribuciones derivadas, ejecuta
sudo apt install git
Cómo utilizar Git
Configuración inicial de Git
Antes de comenzar a utilizar git, necesitas configurar tu nombre e email, los cuales quedarán registrados en los commits que realizas. Para esto, ejecuta:
Necesitas hacerlo una única vez por cada cuenta de usuario que utilices.
Puedes cambiar la configuración por repositorio quitando la opción --global.
Inicialización de un repositorio
El primer paso para trabajar con git es crear un repositorio. Para eso debes posicionarte en el directorio con el cual quieres trabajar (puede estar vacío o no), y ejecutar:
git init
¿Dónde se guarda la información de Git?
Los repositorios contienen la carpeta especial .git , la que tiene una estructura para almacenar la toda la información del repositorio (configuración, historial de cambios, etc). No es recomendable manipular directamente esta carpeta, sólo utilizar opciones de git para hacerlo.
Eliminar esta carpeta destruirá toda la información del repositorio, quedando sólo los últimos cambios en el código. Por lo mismo, también debes tenerlo en consideración al copiar un repositorio a otro lugar.
Registro de cambios
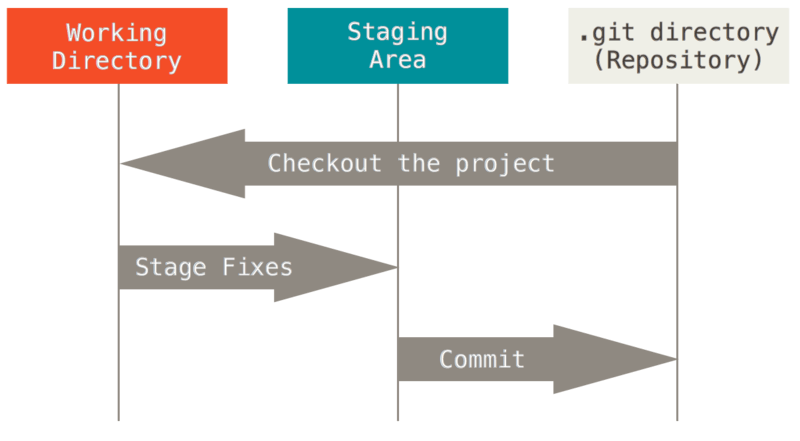
Con un repositorio creado, al hacer cambios (crear, modificar o eliminar archivos) git detectará que existen cambios y asignará nuevos “estados” a estos archivos que indican los cambios realizados. Esta área normalmente se llama working directory. Los archivos nuevos por defecto tienen un estado especial, el cual es untracked.
Estos cambios después deben ser pasados al área de “stage”, que se utiliza como punto intermedio para preparar una revisión (o versión).
Al tener listas las modificaciones se puede registrar una revisión haciendo un commit. A este commit se le asignará un id y quedará en el historial del repositorio, y los archivos que contiene pasarán a estar “no modificados”.
El proceso mediante línea de comandos es:
# añade un nuevo archivo al repositorioecho "Hola mundo!" > README.txt# añade el archivo al área de stagegit add README.txt# registra un commitgit commit -m "Commit inicial"
El comando git add puede recibir más de un archivo como argumento, o incluso un directorios (para incluir el repositorio completo se puede usar “.”).
La opción -m de git commit se utiliza para indicar una descripción del commit, cuyo objetivo es que a simple vista se pueda comprender qué cambios incluye el commit y/o cual es su objetivo.
Los archivos .gitignore
Al ejecutar git add con un directorio como argumentos, o sin argumentos, es común que añadas archivos que no deberían ser parte del repositorio, como archivos de configuración local, archivos temporales de compilación y otros.
Para evitar esto puedes crear un archivo .gitignore en la base del repositorio, que le indicará a git cuáles archivos ignorar. Debes especificar un archivo por línea, y también puedes usar wildcards (*). Por ejemplo:
/config_local.toml # ignora el archivo `config_local.toml` en la base del repositorio*.[oa] # ignora archivos .o y .a, en cualquier directorio del repositoriodata/old/ # ignora el directorio `old` dentro de `data`.tmp/ # ignora los directorios `.tmp/`, en cualquier lugar del repositorio
También puedes crear más de un archivo .gitignore, y en ese caso las rutas ignoradas aplicarán desde el directorio donde esté el .gitignore en lugar de la raíz del repositorio.
Puedes encontrar más información en la documentación.
¿Cómo quitar un archivo del área de stage?
Si el archivo es nuevo, puedes ejecutar git rm --cached ARCHIVO para que vuelva a estar en el estado “untracked”.
Si el archivo ya existe y quieres dejar las modificaciones fuera del área de stage, ejecuta git restore --staged ARCHIVO.
¿Cómo deshacer un commit?
Si hiciste un commit y te das cuenta que tiene un error que necesitas corregir, puedes deshacer el commit usando git reset:
git reset --soft HEAD~1 # deshace el último commit
Después de ejecutar este comando, todo quedará tal cual estaba antes de realizar el commit.
Otra opción es usar git commit --amend, que te permite añadir nuevos cambios al último commit y/o editar el mensaje.
Etiquetas (tags)
Cada commit en Git tienen un id en formato de código hexadecimal, por ejemplo e4b133951ce3c1775a9ce9678480a6d4c39d935c. Este código es un hash, es decir, una firma de verificación del código, la estructura de los archivos y otros metadatos del commit. Recordar este código para identificar un commit en concreto no es sencillo, a pesar de que a menudo se utilizan sólo los primeros caracteres (por ejemplo e4b1339), que git puede reconocer.
Como solución a este problema existen las etiquetas (o tags), que permiten darle un nombre ficticio a cualquier commit, que hace más fácil su identificación, por ejemplo v1.0, o final. Normalmente se utilizan para indicar versiones.
Para añadir una etiqueta a un commit, usa el comando git tag:
git tag v0.1 # asigna la tag v0.1 al commit actualgit tag v0.1 e4b1339 # asigna la tag v0.1 al commit e4b1339...
Para listar las etiquetas, usa git tag -l. Finalmente, si quieres eliminar una etiqueta, usa el comando git tag -d <tag>.
Estado actual del repositorio e historial
El estado actual del repositorio se puede revisar mediante git status. Éste mostrará un resumen de los archivos modificados y el estado en que se encuentran, como éste:
En la rama main
Cambios a ser confirmados:
(usa "git restore --staged <archivo>..." para sacar del área de stage)
modificados: README.txt
Archivos sin seguimiento:
(usa "git add <archivo>..." para incluirlo a lo que será confirmado)
hello.py
Para verificar los cambios que se han realizado desde el último commit, puedes utilizar el comando git diff, el cual puede recibir como argumento uno o más archivos, y de no indicarse ninguno mostrará los cambios de todos los archivos. Por defecto, las diferencias se indican a nivel de líneas, empezando con - las líneas eliminadas y con + las líneas nuevas.
diff --git a/README.txt b/README.txtindex 3dff84f..6e87af1 100644--- a/README.txt+++ b/README.txt@@ -1,2 +1,3 @@ Hola mundo!-Este es un primer mensaje+Este es un mensaje+Y este es otro mensaje
Para visualizar el historial de commits existe el comando git log --graph. Este comando mostrará los id de los commits, sus descripciones y un diagrama indicando la línea temporal del repositorio, incluyendo ramas.
¿Cómo moverse entre versiones?
El comando git checkout te permite moverte entre versiones, ramas y etiquetas. Sólo debes pasar como parámetro hacia donde quieres ir. Para indicar versiones relativas a la actual (“la anterior a ésta”, o “dos commits atrás”) utiliza HEAD~n, con n indicando cuántos commits atrás quieres ir. Para volver la última versión, utiliza el nombre de la rama (comúnmente main).
Algo a tener en consideración, es que Git no te dejará hacer checkout si hay cambios pendientes. Pero para eso puedes utilizar git stash.
Ramas (branches)
Las ramas permiten la coexistencia de múltiples líneas de desarrollo del código, lo cual es útil para realizar pruebas o desarrollar nuevas características sin afectar la base estable del código. Las ramas tienen algún punto de inicio común del cual se bifurcan, y cada una puede tener uno o más commits que son únicos para la rama.
Es común que en algún momento quieras volver a “unir” las ramas, y este proceso se le llama merge. Dependiendo los conflictos que existan entre las ramas, el proceso de merge puede llegar a ser complejo ya que requiere de una revisión manual de los cambios a conservar.
La rama por defecto normalmente es llamada “main” o “master” y al crear una nueva rama puedes especificar el nombre que quieres.
En el siguiente ejemplo, creamos la rama develop a partir de la rama main, y luego hacemos un merge a la rama main nuevamente, donde unimos los cambios que comprenden los commits 2 al 4.
gitGraph
commit
commit
branch develop
checkout develop
commit
checkout main
commit
checkout develop
commit
checkout main
merge develop
commit
commit
En la línea de comandos, esto se realiza así:
# asumiendo que estamos en main# crea la rama develop como bifurcación de maingit branch develop# cambia a la rama developgit checkout develop# crea un nuevo committouch test.txtgit add test.txtgit commit -m "New commit"# cambia a rama maingit checkout main# hace merge de la rama develop hacia la rama maingit merge develop
Combinación cambios divergentes con merge
El proceso de merge en Git es fundamental cuando se trabaja en proyectos con múltiples ramas, ya que permite combinar los cambios de una rama con otra.
Para hacer un merge, debes seguir los siguientes pasos:
Cambiar a la rama de destino: Asegúrate de estar en la rama en la que deseas integrar los cambios. Por ejemplo, si deseas fusionar los cambios de la rama feature en main, primero debes cambiar a main:
git checkout main
Realizar el merge: Luego, ejecuta el comando de merge, indicando la rama de la cual deseas integrar los cambios:
git merge feature
Si no hay conflictos, Git combinará automáticamente los cambios y creará un nuevo commit de merge.
Verificar el resultado: Finalmente, puedes usar git log o git status para verificar que el merge se haya realizado correctamente.
En el paso 2 puede ocurrir una de dos cosas:
Merge sin conflictos: Cuando los cambios en las ramas a combinar no se superponen, el proceso de merge es sencillo y Git lo puede completar automáticamente. Esto significa que el comando se ejecutará sin pedir nada y los cambios serán integrados.
Merge con conflictos: Cuando un mismo archivo ha sido modificado de forma incompatible en ambas ramas, git no podrá resolver estos conflictos automáticamente, por lo que necesitarás intervenir manualmente. Git indicará las secciones con conflictos con <<<<<<<, ======= y >>>>>>>, por ejemplo:
<<<<<<< HEAD
Código en la rama main
=======
Código en la rama feature
>>>>>>> feature
Debes editar el archivo para resolver los conflictos, eliminando las marcas de conflicto y dejando el código que deseas conservar. Luego, añade los cambios al área de stage y haz un nuevo commit para finalizar el proceso:
Copias remotas de un repositorio
Una de las principales características de Git, es permitir la sincronización con copias remotas de un repositorio. Esto puede ser útil para trabajar con más personas en un mismo proyecto o simplemente como respaldo. Las copias remotas pueden estar en un directorio del mismo equipo, un equipo remoto o una plataforma como GitHub o GitLab.
En primer lugar debemos añadir una copia remota. Cada repositorio puede tener más de una. El comando para realizar esto es:
En este comando, origin es el nombre que le pondremos a la copia remota, y git@github... es la URL mediante la cual se puede acceder a este repositorio. Para listar todas las copias remotas de un repositorio existe el comando git remote -v.
Protocolos de acceso a repositorios Git
Git soporta dos protocolos para acceder a repositorios remotos: SSH y HTTPS.
Puedes conocer cuál protocolo se está utilizando mediante la url utilizada:
si tiene la forma git@miservidorgit.xyz/mi-repo es mediante SSH
si la url es del tipo https://miservidorgit.xyz/mi-repo es HTTPS
Las plataformas como GitHub o GilLab permiten ambos métodos de acceso. Lo más común es utilizar SSH si queremos realizar cambios en el repositorio, y HTTPS si queremos una copia de sólo lectura.
Para hacer la sincronización existen los comandos “pull” y “push”, que obtienen y envían la información de un repositorio, respectivamente. Estos pueden recibir opcionalmente la rama que se desea enviar o recibir (si no se indica, utilizará la rama por defecto).
En línea de comandos:
# obtiene los datos de la copia remotagit pull# envia los datos hacia la copia remotagit push
Si quieres descargar un repositorio completo, utiliza el comando git clone <url>. Esto descargará el repositorio con su rama principal e historial.
Autenticación por SSH en GitHub
Para tener acceso a repositorios privados en GitHub o para enviar cambios a cualquier repositorio, necesitas autenticarte mediante SSH. Este proceso utiliza una combinación de clave pública/privada. A continuación, se detallan los pasos para configurar la autenticación por SSH:
Generar una nueva clave SSH: Ejecuta el siguiente comando para crear una nueva clave:
ssh-keygen -t ed25519
Este comando te preguntará dónde guardar la clave. Usa el valor por defecto (presiona Enter). Luego, te pedirá una “passphrase”, que es básicamente una contraseña que será solicitada cada vez que uses la clave. Puedes dejarlo vacío si no deseas establecer ninguna.
Ubicación y contenido de las claves: Una vez completado el proceso, se generarán dos archivos en el directorio ~/.ssh/:
id_ed25519: Esta es tu clave privada. No debes compartirla con nadie y debe quedar guardada en tu equipo. Puedes copiarla a otros equipos si deseas usar la misma clave desde múltiples lugares.
id_ed25519.pub: Esta es tu clave pública, la cual debes registrar en servidores remotos (en este caso, GitHub).
Registrar la clave pública en GitHub: Para ingresar tu clave pública en GitHub:
Navega a Settings > SSH and GPG Keys.
Presiona en New SSH key.
En el formulario que se abre, pega el contenido de tu clave pública (id_ed25519.pub) en el campo Key. Puedes dejar el campo Title vacío o poner un nombre descriptivo.
Haz clic en Add SSH key.
Verificar la autenticación: Para asegurarte de que la clave SSH está correctamente configurada, ejecuta el siguiente comando:
ssh -T git@github.com
Si la configuración es correcta, deberías ver un mensaje de bienvenida con tu nombre de usuario.
Siguiendo estos pasos, habrás configurado correctamente la autenticación por SSH en GitHub, lo que te permitirá clonar, enviar cambios y acceder a repositorios privados de manera segura.
Resumen de Conceptos de Git
Repositorio: Es el conjunto de archivos y carpetas que se encuentran bajo el control de Git. En general, se trata de un directorio en el sistema de archivos.
Commit: Es un conjunto de cambios que se han realizado en el repositorio. Cada commit tiene un identificador único, que se genera a partir de los cambios realizados.
Branch (rama): Es una línea de desarrollo independiente. En general, se utiliza para desarrollar una nueva funcionalidad, sin afectar el código de la rama principal. Una vez que la funcionalidad está lista, se puede integrar a la rama principal.
Merge (fusión): Merge es el acto de combinar los cambios de una rama a otra. Al fusionar una rama, estás tomando todos los commits que se hicieron en esa rama y los estás aplicando a otra rama.
Pull: Es “descargar” los cambios de un repositorio remoto y aplicarlos al repositorio local. Esto es útil cuando estás trabajando en un equipo y quieres obtener los últimos cambios que tus compañeros han subido al repositorio remoto.
Push: Un “push” es el acto de enviar tus cambios a un repositorio remoto. Esto permite a otros usuarios de tu repositorio ver y acceder a tus cambios.
Clone: Clone (clonar) es el acto de copiar un repositorio remoto a tu máquina local. Esto te da una copia de todo el historial del proyecto y te permite trabajar en él localmente.